How Much Do Data Scientists Need to Know About Statistics?

Data science is a multi-faceted, interdisciplinary field of study. It’s not just dominating the digital world. It’s integral to some of the most basic functions - internet searches, social media feeds, political campaigns, grocery store stocking, airline routes, hospital appointments, and more. It’s everywhere. What makes data science so applicable to the human experience? Among other disciplines, statistics is one of the most important disciplines for data scientists.
Josh Wills, a former head of data engineering at Slack, said “A data scientist is a person who is better at statistics than any programmer and better at programming than any statistician.”
In other words, statistics is an inherently necessary component of data science. We’ll explore more on this concept below, in addition to the best ways for learners to gain statistical knowledge for a data science position.
Introduction to statistics for data science
Statistical analysis and probability influence our lives on a daily basis. Statistics is used to predict the weather, restock retail shelves, estimate the condition of the economy, and much more. Used in a variety of professional fields, statistics has the power to derive valuable insights and solve complex problems in business, science, and society. Without hard science, decision making relies on emotions and gut reactions. Statistics and data override intuition, inform decisions, and minimize risk and uncertainty.
In data science, statistics is at the core of sophisticated machine learning algorithms, capturing and translating data patterns into actionable evidence. Data scientists use statistics to gather, review, analyze, and draw conclusions from data, as well as apply quantified mathematical models to appropriate variables. Data scientists work as programmers, researchers, business executives, and more. However, what all of these areas have in common is a basis of statistics. Thus, statistics in data science is as necessary as understanding programming languages.
Towards Data Science, a website which shares concepts, ideas, and codes, supports that data science knowledge is grouped into three main areas: computer science; statistics and mathematics; and business or field expertise. These areas separately result in a variety of careers, as displayed in the diagram below. Combining computer science and statistics without business knowledge enables professionals to perform an array of machine learning functions. Computer science and business expertise leads to software development skills. Mathematics and statistics (combined with business expertise) result in some of the most talented researchers. It is only with all three areas combined that data scientists can maximize their performance, interpret data, recommend innovative solutions, and create a mechanism to achieve improvements.
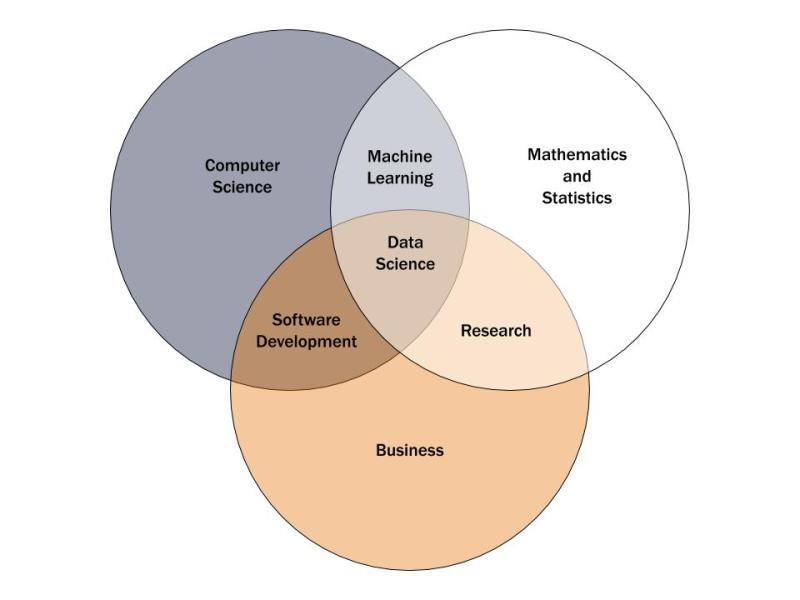
Source: Towards Data Science
Statistical functions are used in data science to analyze raw data, build data models, and infer results. Below is a list of the key statistical terms:
- Population: the source of data to be collected.
- Sample: a portion of the population.
- Variable: any data item that can be measured or counted.
- Quantitative analysis (statistical): collecting and interpreting data with patterns and data visualization.
- Qualitative analysis (non-statistical): producing generic information from other non-data forms of media.
- Descriptive statistics: characteristics of a population.
- Inferential statistics: predictions for a population.
- Central tendency (measures of the center): mean (average of all values), median (central value of a data set), and mode (the most recurrent value in a data set).
- Measures of the spread:
- Range: the distance between each value in a data set.
- Variance: the distance between a variable and its expected value.
- Standard deviation: the dispersion of a data set from the mean.
Statistical techniques data scientists need to master
Data scientists go beyond basic data visualization and provide enterprises with information-driven, targeted data. Advanced mathematics in statistics tightens this process and cultivates concrete conclusions.
Statistical techniques for data scientists
There are a number of statistical techniques that data scientists need to master. When just starting out, it is important to grasp a comprehensive understanding of these principles, as any holes in knowledge will result in compromised data or false conclusions.
General statistics: The most basic concepts in statistics include bias, variance, mean, median, mode, and percentiles.
Probability distributions: Probability is defined as the chance that something will occur, characterized as a simple “yes” or “no” percentage. For instance, when weather reporting indicates a 30 percent chance of rain, it also means there is a 70 percent chance it will not rain. Determining the distribution calculates the probability that all those potential values in the study will occur. For example, calculating the probability that the 30 percent chance for rain will change over the next two days is an example of probability distribution.
Dimension reduction: Data scientists reduce the number of random variables under consideration through feature selection (choosing a subset of relevant features) and feature extraction (creating new features from functions of the original features). This simplifies data models and streamlines the process of entering data into algorithms.
Over and under sampling: Sampling techniques are implemented when data scientists have too much or too little of a sample size for a classification. Depending on the balance between two sample groups, data scientists will either limit the selection of a majority class or create copies of a minority class in order to maintain equal distribution.
Bayesian statistics: Frequency statistics uses existing data to determine the probability of a future event. Bayesian statistics, however, takes this concept a step further by accounting for factors we predict will be true in the future. For example, imagine trying to predict whether at least 100 customers will visit your coffee shop each Saturday over the next year. Frequency statistics will determine probability by analyzing data from past Saturday visits. But Bayesian statistics will determine probability by also factoring for a nearby art show that will start in the summer and take place every Saturday afternoon. This allows the Bayesian statistical model to provide a much more accurate figure.
Statistical skills needed to perform data science jobs
Data science requires a mixture of technical skills, such as R and Python programming languages, as well as “soft skills,” including communication and attention to detail. Here are several of the most important skills data scientists need to hone in order to strengthen statistical abilities.
Data manipulation: Using Excel, R, SAS, Stata, and other programs, data scientists have the ability to clean and organize large data sets.
Critical thinking and attention to detail: Using linear regression, data scientists extract and model relationships between dependent and independent variables. Data scientists choose methods with built-in assumptions which are considered during their application. Violating or inappropriately choosing assumptions will lead to flawed results.
Curiosity: The desire to solve complex puzzles drives data scientists to design data plots and explore assumptions. They also discover patterns and sequences by using advanced data visualizations.
Organization: Data scientists are inundated with information from various sources and ongoing project opportunities. With budget and time constraints, data scientists perform efficiently when they are well-versed in statistical functions. In addition, having routinized processes helps ensure data is not compromised.
Innovation and problem solving: Above and beyond pure computations and basic data analysis, data scientists use applied statistics to pair abstract findings to real-world problems. Data scientists also use predictive analytics to determine future courses of action. All of this requires careful consideration, using both logical and innovative approaches to analyze issues and solve problems.
Communication: All of the work a data scientist does must be translated into a captivating story that industry leaders and executives can appreciate. Data scientists fill the gap between technology and operations. They translate findings into text and data visualizations that executives and clients can easily understand: an essential skill for a data scientist.
Statistics: Data scientists should consider learning statistics, because statistics connects data to the questions businesses are asking across all disciplines. Questions including:
- How can we create efficiencies?
- How can we limit spending and increase revenue?
- How can we maximize communications with our target audience?
How to learn statistics for data science
Data scientist shortages have pushed enterprises to get creative while trying to fill the data talent gap. Some companies retrain existing staff in-house or arrange for graduate study in data science. Regardless of the method, education is the central force driving these efforts. Three popular educational paths are massive open online courses (MOOCs), bootcamps, or master’s programs. While the data science education options leave employers wondering which path is best, masters degree programs have traditionally been the most valued among the three.
The best education in data science depends upon matching a student’s needs with the most appropriate training resources. The process of learning statistics in data science, for instance, will look different depending on a person’s educational and professional background. It is reasonable for a data science professional who has already acquired a data science foundation to sharpen their probability techniques through a variety of learning options. However, a recent college graduate, however, will find the deepest comprehensive data science training through a data science master’s program.
Here is a quick glance at the pros and cons of learning data science through MOOCs, bootcamps, and master’s degrees.
Statistics in data science

MOOCs
While MOOCs in data science cannot replace the value of a comprehensive graduate program, they can help students refresh their knowledge on the basics. MOOCs are a cost-free option for data science professionals who need to brush up on statistics and mathematics skills. Current data science professionals benefit from online material by learning the latest trends and techniques, as the field is constantly changing. MOOCs are also useful for individuals who are on the fence about entering the field of data science. Especially when free, a MOOC is a low-risk method for testing out the field and seeing whether data science is worth pursuing.
Here are a few top-rated MOOCs in data science:
- IBM: AI Enterprise Workflow Specialization
- IBM: AI Engineering Professional Certificate
- IBM: Data Visualization with Python
- IBM: Machine Learning with Python
- Google: AI
- Google Cloud: Machine Learning with TensorFlow on Google Cloud Platform Specialization
- Google Cloud: Machine Learning for Business Professionals
- SAS: Academy for Data Science
- SAS: Machine Learning Using SAS
- MathWorks: Practical Data Science with MATLAB Specialization
- Deeplearning.ai: Deep Learning Specialization
- KDnuggets also posts courses and boot camps in artificial intelligence (AI), big data, data science, machine learning
Bootcamps
With the growth of data science careers, educational institutions responded to the need for data skills by expanding vocational programs, such as data bootcamps. Data science bootcamps are compact, intensive educational programs that teach students the basic principles in data science. The goal for each bootcamp graduate is to be able to successfully interview for a data science role and ultimately be hired into the field.
While bootcamps are useful, they are typically not comprehensive programs, often taking only six months or less to complete. Data science bootcamp leaders sometimes cut corners by focusing curriculum on topics and skills that are covered in a data science job interview. This provides support and training for immediate job outcomes, but it is not as sustainable as the long-term career planning a master’s degree offers.
Master’s degree
A master’s program curriculum covers all the fundamentals of data science. It also provides real-world skills and the ability to continue learning, which bootcamps simply do not have time to cover. When planning an education trajectory, ask yourself the following questions about the university you are considering:
- Do graduate candidates have an opportunity for real-world experience?
- What is the career trajectory of others who have gone through the program?
- What is the average salary of a person with this education and training?
- Is the program flexible? Will it fit with my lifestyle?
- Do reputable companies hire directly from the program?
- What kind of support do you get when you’re done with the program?
The path toward a rewarding and challenging data science career begins with a strong graduate studies foundation, followed by the expansion of your machine learning portfolio and ongoing learning and sharpening of statistical literacy and programming skills.
Courses in statistics for data science
Statistics is a core component of programs such as the University of Virginia’s online Master of Science in Data Science (MSDS). Our program provides the following benefits:
- Flexibility — you do not have to put your life on hold. Continue working, start an internship, or fulfill other life obligations while continuing your education.
- While the program is rooted in the UVA School of Data Science, you do not have to uproot your life and relocate to Virginia. Classes are taken from any location.
- You will demonstrate your ability to be self-motivated and practice good time management.
- As working habits evolve to offer more fully-online jobs, you will have the advantage of beginning your data science career with remote experience.
- Gain knowledge and experience with a rigorous and forward-thinking online program, as well as internship opportunities, which will provide you with the competitive edge you need to achieve your data science career goals.
MSDS program applicants are required to possess an undergraduate degree before beginning the program. While a background in computer science is welcome, it is not required. In fact, students come from a variety of undergraduate backgrounds, including economics, statistics, engineering, computer science, math, hospitality management, and liberal arts.
Students must complete each of the following prerequisites prior to the start of the summer term in which the program starts:
- Single variable calculus
- Linear algebra or matrix algebra
- Introductory statistics
- Introductory programming
Data science courses
As part of UVA’s online MSDS program, the following technical courses require a background in introductory statistics:
Linear Models for Data Science: This course is an introduction to linear statistical models in the context of data science. Topics include simple and multiple linear regression, and generalized linear models. The primary software is R.
Foundations of Computer Science: This course provides a foundation in discrete mathematics, data structures, algorithmic design and implementation, computational complexity, parallel computing, and data integrity and consistency for non-CS, non-CpE students. Case studies and exercises will be drawn from real-world examples (e.g., bioinformatics, public health, marketing, and security).
Practice and Application of Data Science I and II: This course covers the practice of data science, including communication, exploratory data analysis, and visualization. Also covered are the selection of algorithms to suit the problem to be solved, user needs, and data. Case studies will explore the impact of data science across different domains.
Machine Learning: A graduate-level course on machine learning techniques and applications with emphasis on their application to systems engineering. Topics include Bayesian learning, evolutionary algorithms, instance-based learning, reinforcement learning, and neural networks. Students are required to have sufficient computational background to complete several substantive programming assignments. Prerequisite: A course covering statistical techniques, such as regression.
Strengthen your statistics skills at the UVA online MSDS
A master’s degree in data science — such as the residential or online MSDS offered at UVA’s School of Data Science — prepares graduates for both immediate job opportunities and long-term career planning. Machine learning models and statistical techniques will continue to evolve, but a graduate degree offers a solid foundation so students can quickly adapt with technological changes. Data science is also about helping people solve problems through collaboration. UVA’s online MSDS allows students to develop lasting relationships with both fellow students and faculty. These networking opportunities can offer students internship and professional opportunities throughout their careers, and foster enriching relationships for the rest of their lives.