Image


Critical AI, Duke University Press | April 2024
The strengths and weaknesses of generative applications built on large language models are by now well-known. They excel at the production of discourse in a variety of genres and styles, from poetry to programs, as well as the combination of these into novel forms. They perform well at high-level question answering, dialogue, and reasoning tasks, suggesting the possession of general intelligence. However, they frequently produce formally correct but factually or logically wrong statements. This essay argues that such failures—so-called hallucinations—are not accidental glitches but are instead a by-product of the design of the transformer architecture on which large language models are built, given its foundation on the distributional hypothesis, a nonreferential approach to meaning. Even when outputs are correct, they do not meet the basic epistemic criterion of justified true belief, suggesting the need to revisit the long neglected relationship between language and reference.
If you had to identify a single big idea to characterize twentieth-century thought in the humanities and interpretive social sciences, it would be that language is an internally organized system of signs that are arbitrarily linked to concepts that are distantly, if at all, related to things in themselves. In this view, language is accorded high epistemic autonomy: its internal operations, within minds and across societies, shape thought and knowledge independently of other forms of representation or experience. This autonomy is so pronounced that the physical traces left by these operations—the written words abstracted from documents—are believed to provide a sufficient basis to infer the meanings and truth values associated with knowledge claims. Both the analytical philosopher's logical manipulation of p's and q's and the deconstructionist's rhetorical exploitation of paronomasia and polysemy are pure operations of the linguistic sign—they do not require the external support of either experimental science or experiential learning, only the connections of signs to other signs. In place of a theory about the relationship between individual signs and things in the world, some variants of this idea promote high-level (and unverifiable) understandings of the relationship between language as a whole and a series of primary ontological substances—power, history, sexuality, evolution, energy. In each case, this relationship is treated as given and the problem of how individual words are connected to things in the world is left to one side, regarded as a nonproblem of interest only to the naive and uninitiated. Although this idea was explicitly argued for by Saussure and the structuralists who followed him, it operated as a tacit belief that crosscut disparate thinkers across a variety of disciplines that would not claim the linguist as an ancestor, a deeply rooted premise characteristic of a mentalité within the academy. Call it the dogma of linguistic autonomy.
This dogma no longer dominates intellectual life in the twenty-first century, but it lives on in the field of natural language processing (NLP) and the large language models (LLMs) that power tools like Open AI's ChatGPT. The vehicle for its survival is the distributional hypothesis of linguistic meaning, an idea first developed in a scientific way by the American structural linguist Zellig Harris (1954), a disciple of Leonard Bloomfield and teacher of Noam Chomsky. According to this idea, word meanings can be inferred from the statistical distributions of their co-occurrences with other words, as opposed to an investigation into their referents and definitions or an account of their grammatical rules of production. In Harris's formulation, such a description “is complete without intrusion of other features such as history or meaning” and “distributional statements can cover all the material of a language, without requiring support from other types of information.”
The intuition behind the hypothesis is that words that occur in similar lexical contexts have similar meanings. In the words of the English linguist J. R. Firth (1957), “You will know a word by the company it keeps!” Put another way, words with similar meanings can substitute for each other in otherwise identical sentences. It is this principle of substitutability that many theorists found compelling enough to develop an entire epistemology, one based on the concepts of opposition and difference. Both structuralists and deconstructionists committed to the idea that the meaning of a word in an utterance is purely a function of what could have been said, given the set of all possible substitutions for that word (its sample space). In doing so, they shifted the study of meaning away from the ethnographer's focus on the shared situation, or Umwelt, of speakers and listeners, or the critic's concern with an author's intent, and toward uncovering the latent network of words and meanings among texts stored by libraries and organized by institutions.
LLMs are built firmly on top of an operationalized version of the distributional hypothesis. Operationalization is a technical but ultimately interpretive process by which a received theory from some body of knowledge, often from the humanities or social sciences, is represented in a form that can be measured and processed by machine (Moretti 2013; Alvarado 2019). In the case of LLMs, a pillar of pre-Chomskyan structural linguistics informs the design of a set of data structures and algorithms intended to extract a language model from a corpus of text. Specifically, the distributional hypothesis informs the construction of word “embeddings”—vector-based representations of linguistic meaning that are used to train language models. Because these vectors are the primary informational material out of which an LLM is inferred, an understanding of their design is crucial to our ability to critically assess what LLMs know—that is, to understand what kinds of knowledge claims LLMs are capable of making.
Although the mathematical models and algorithms required to learn the parameters of a word embedding model are complex, the intuition behind them is simple. Everything begins with the representation of a corpus as a kind of concordance of keywords in context. In effect, each word in the training corpus (for example, the entirety of English Wikipedia) is associated with every other word in which it appears in a given context. One way that models differ is in how they define context. Two popular definitions are as a fixed “bag” of words (say, a paragraph) or as a sliding window of words. If the context is a sliding window of two words (or sentence boundaries) that precede or follow a given word, we would represent the sentence “The quick brown fox jumped over the lazy dogs” as follows:
The underlined, bolded words are called anchor words, while the flanking bolded words are context words. These can be extracted and stored in a table (fig. 1). The XML-like tags for the beginnings and ends of sentences in the table are added to ensure that the word contexts do not cross sentence boundaries, given the status of the sentence, or utterance, as the elementary unit of discourse. It is possible to add other features (columns) here, such as the distance of the context word from the anchor word, a value that ranges from −2 to 2.
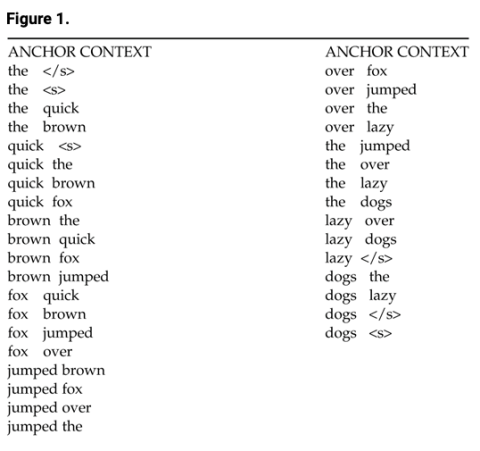
In this example the sliding window of words is converted into a two-column table of co-occurrences. When applied to an entire corpus, these data may be used to estimate a model for the distribution of each word in the language represented by the corpus, as well as the conditional probabilities of words that follow a given word. These may be inferred through a variety of methods, such as by estimating a probability model by treating the relative frequencies as joint probabilities, by training a neural network to predict an anchor word from its context and then extracting the matrix of learned weights, or by converting the table into an anchor-word-by-context-word count matrix and decomposing it through linear algebra. Whatever the method, the result is a table of word embeddings.
An embedding is a vector, or list, of numbers associated with the features that are extracted from the co-occurrence data using the chosen method. These vectors may be imagined as coordinates in a multidimensional space, where each feature is a dimension. The number of features in the embedding vector will be smaller, by orders of magnitude, than the total vocabulary in the data from which they are derived. A typical word embedding model might have two hundred features extracted from a co-occurrence matrix generated by two hundred thousand distinct words.
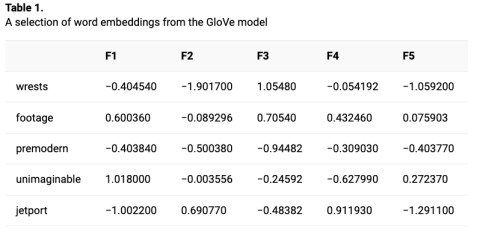
Table 1 represents a sample from one of Stanford's Global Vectors for Word Representation (GloVe) models; it shows the first five of fifty features for five randomly drawn words (Pennington, Socher, and Manning 2014).
On its own, this table is a very powerful tool for exploring word meanings and thesaurus-like relationships. It can be used to discover similar words by measuring the distance between their vectors. For example, the top ten most similar words in this model to queen are princess, lady, Elizabeth, king, prince, coronation, consort, royal, and crown. It can also be used to infer the missing terms of an analogy by the addition and subtraction of vectors—a kind of semantic algebra. For example, by converting the proportion A : B :: C : D into the equation B – A + C ≈ D, we can deduce that if kings are male then queens are probably female. Because these similarities and analogies are dependent on the text collections on which they are trained, they may be used to explore cultural biases and historical changes in usage (Durrheim et al. 2023; Hamilton, Leskovec, and Jurafsky 2016). In effect, then, a word embedding table is a kind of dictionary. It literally represents the meaning of each word in a language as understood by the distributional hypothesis and as witnessed by the particular concordance on which it is trained.
The transformer architectures that contemporary LLMs are based on are built on the representation of language as a collection of word embeddings (Vaswani et al. 2017). In the first place, LLMs are fed word sequences that are converted into embeddings drawn from a pretrained model, such as one of the GloVe models. These embeddings are combined with positional encoding vectors and then trained on using an attention mechanism to produce context-specific word embeddings.1 These contextual embeddings allow for the disambiguation of polysemy, the detection of nuance relating to such factors as genre and sentiment, and the capture of long-range relationships between words in the input sequence, producing far more accurate predictions of next words (and sentences). In short, LLMs achieve their linguistic abilities by introducing contextual, or local, embeddings that extend the static, or global, embeddings produced by models like GloVe and word2vec.
LLMs, then, by virtue of their use of word embeddings, further operationalize the distributional hypothesis; they introduce no new linguistic information (syntactic, semantic, or pragmatic) that would improve upon or extend the nonreferential conception of meaning on which the hypothesis is based. Given this, it would seem that LLMs provide an empirical test of a theory of meaning that, in truth, has never been tested. After all, the distributional hypothesis has its origins in speculative philosophy (Wittgenstein's “the meaning of a word is its use”) and the largely unfulfilled programmatic expectations of the structural linguists who preceded Chomsky.
Viewed this way, the results are compelling but mixed. LLMs are clearly quite good at some forms of “reasoning,” performing extremely well on tasks ranging from writing code to passing entrance exams. They also perform very well at some fairly sophisticated writing tasks, such as producing formally correct poems (e.g., sonnets) or changing the style, voice, or tone of a text. Where they fail is in their capacity to be truthful. Notoriously, they are prone to “hallucinating,” producing sentences that are formally correct but completely untrue (OpenAI 2023). Such errors of fact are commonplace, although they are becoming less frequent with more recent agents, such as ChatGPT, as these are being tutored with extensive human feedback to not produce answers that are considered untrue, biased, or harmful.
It is important to recognize that these errors are not occasional lapses but direct consequences of their hard coding of the distributional hypothesis. Even when LLMs produce ostensibly true sentences, they do so accidentally—these sentences are all cases of what epistemology calls unjustified true belief. They are unjustified because the systems that generate them do not incorporate any of the mechanisms by which humans seek or validate truth claims, either rationally or empirically. And although it may be possible to encode axiomatic reasoning into these systems—they are, after all, fruits of the rationalist tradition in philosophy—the possibility of empirical or pragmatic grounding is excluded because of the absence of referential meaning in their design, a consequence of their adherence to the dogma of linguistic autonomy. As such, the false outputs of LLMs are not so much hallucinations as they are the products of a built-in aphasia, a communicative disorder in which agents produce coherent speech without understanding anything they are saying or why they are saying it. To paraphrase G. K. Chesterton, these agents are missing everything but their reason.
In conclusion, one way to view an LLM is as a counterfactual simulation of a world in which referential meaning has been excluded. In this world, what works and what does not? From the evidence, one response is to plead for a return to the concept of reference, a concept that has been demoted as a source of meaning ever since Gottlob Frege's (2021) privileging of sense over reference (first published in German in 1892) and the demise of Wittgenstein's ([1922] 2001) caricature of the concept, the picture theory of language. Such a return would embrace the rich ethnographic and ethnohistoric understandings of language, in which meaning is framed not simply as a function of a sign's place in a matrix of differences but the result of that system being continually deployed and altered by living human beings engaging with the material and social world. These understandings include the concept of situated action promoted by Lucy Suchman (1987) in her early and still relevant critique of AI, the concept of referential practice developed by William Hanks (2005), and the historical critique and retrieval of structuralism developed by Marshall Sahlins (1985), whose concept of referential risk seems particularly appropriate to this conversation:
In action, people put their concepts and categories into ostensive relations to the world. Such referential uses bring into play other determinations of the signs besides their received sense, namely the actual world and the people concerned. Praxis is, then, a risk to the sense of signs in the culture-as-constituted, precisely as the sense is arbitrary in its capacity as reference. Having its own properties, the world may then prove intractable. It can well defy the concepts that are indexed to it. Man's symbolic hubris becomes a great gamble played with the empirical realities. The gamble is that referential action, by placing a priori concepts in correspondence with external objects, will imply some unforeseen effects that cannot be ignored.
We would do well to consider this perspective, especially as these models are being deployed not as research tools in the study of language but as real agents in the political and economic spheres of our collective lives.
For Notes and Works Cited, reference the original article published on Duke University Press.
Subscribe to receive updates from the School of Data Science.



