A Week in the Life: First-Year Ph.D. Student
 Being a first-year Ph.D. in the School of Data Science (SDS) is an exciting time. As a first-year student, most of my focus is on classwork and mastering the data science tools we will use throughout the program. Our first year is a fellowship, which means that we are not required to participate in research or serve as a Graduate Teaching Assistant (GTA). This gives us the time and space to focus on learning and engage in research only if we choose which I decided to do by working in Professor Perrin’s lab.
Being a first-year Ph.D. in the School of Data Science (SDS) is an exciting time. As a first-year student, most of my focus is on classwork and mastering the data science tools we will use throughout the program. Our first year is a fellowship, which means that we are not required to participate in research or serve as a Graduate Teaching Assistant (GTA). This gives us the time and space to focus on learning and engage in research only if we choose which I decided to do by working in Professor Perrin’s lab.
My typical weekly schedule looks like this:
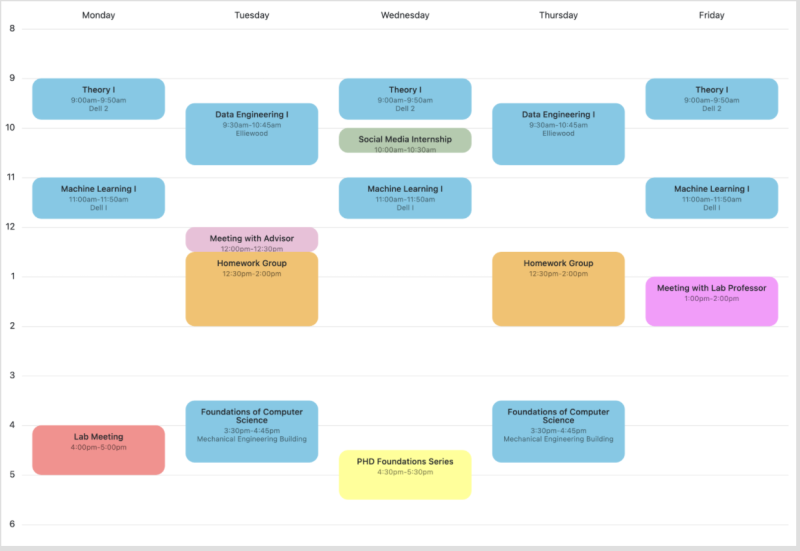
Classes
Our first-year classes are Theory I (Probability and Stochastic Processes), Machine Learning I, Data Engineering I, and Foundations of Computer Science. Theory I focuses on learning probability theory and finding and comparing analytically generated solutions to real-world probability problems to simulation-generated solutions using R. Machine Learning I emphasizes the foundations of machine learning, including linear regression, logistic regression, random forests, ordinal regression, and nonlinear models in R. Data Engineering I examines the entire data science pipeline from collecting/scraping data all the way through presenting it in a compelling format through a dashboard. Data Engineering I primarily uses Python for programming. Foundations of Computer Science teaches us the fundamentals about how computers capture, manipulate, and encode data, including algorithms, graphs, and trees. The course is mostly theoretical, although we do some programming in Python.
Research
Working in a lab as a Ph.D. student typically involves three components: meeting with the whole lab team, meeting 1:1 with the faculty researcher/mentor, and doing individual assigned tasks. Professor Perrin’s lab meets every other week, and I meet with him 1:1 every other week as well. In between meeting weeks, I work on any tasks I am assigned.
Professional Development
There are many professional development opportunities available to a Ph.D. students. One key resource is PhD+, which offers non-credit professional development workshops available to all UVA Ph.D. students. In these workshops, you can learn anything from budgeting as a Ph.D. student to how to write and refine grant proposals.
Another excellent opportunity is the SDS weekly Data Science Symposiums, which are hour-long data science seminars from SDS/UVA faculty and guest speakers. The Data Science Symposiums are a wonderful way for Ph.D. students to network and gain exposure to field experts and leading research across the data science industry.
First-year Ph.D. students are also able to engage in internships for professional development. I work as a Social Media Intern for the Communications Team. It’s been a fantastic way to hone my communication skills and help others learn about the exciting things going on at SDS.
Collaboration
A key component of the SDS Ph.D. program is teamwork. All our problem sets and projects allow collaboration because that’s typical of data science in both academia and industry. In between classes, we often get coffee together and work on our assignments. It is a great way to bond while being productive! When not working with my classmates and in the evenings, I often work independently on readings or finishing assignments.
Extracurricular Fun
Being a Ph.D. student at UVA also means you have access to UVA clubs, recreational sports, gyms, and free tickets to sporting events. In my free time, I like to go to Memorial Gymnasium to work out. I also like to attend UVA football games on the weekends in the fall. One of my other favorite pastimes is to go to the Alamo to see a movie with my friends and classmates. This week, I got to enjoy the re-release of the Avatar movie!
